Archive → September, 2009
Mobile Libraries
On Thursday I blogged the presentation of the Erewhon project based at Oxford University. I promised that I would follow up with a post on how I thought the project was relevant to the work TELSTAR is doing – so here goes.
One of the services that Erewhon is looking at delivering is something like being able to answer the question ‘where is the nearest (Oxford University) library to my current location where I can get this book/journal/other?’. This relates very much to questions that we’ve been discussing for TELSTAR and I’ve already blogged about – given a reference, what is the route of access to the resource being referenced.
The TELSTAR project is focussing on answering that question with respect to the online resources offered by the Open University via the Library service. This is clearly a great starting point, and as we deliver more and more resources electronically, it becomes more likely that for any particular resource we can deliver it electronically.
However, what about those things that aren’t delivered as part of the course materials, and we can’t provide electronically via the library? This is where we want to start being able to respond more to a particular users ‘context’ – and where they are is a good place to start. It would be great to be able to answer the question “where is the nearest library to me that I can get this book?”or perhaps more generically “where is the nearest library to me that I can access this resource?”. The latter question is important because you may be able to access electronic resources by going into a library – often licenses enable libraries to offer ‘walk-in’ access to electronic resources to visitors.
There are some services that already try to answer these questions. Worldcat can answer this question for libraries that have their records in Worldcat. Talis have setup a directory of libraries, including location details, which might be used to generate this type of service (as Chris Keene demonstrated at the Mashed Library 2008 event). If we could combine this type of service with the type of Geo-location work Erewhon is doing then we could start to answer these questions. It’s a shame that the SCONUL Access scheme database doesn’t seem to have an API to get details of local libraries.
However, this is focussing on the physical collections – I’m also interested in the electronic. Within TELSTAR we are pushing all our links via our SFX OpenURL resolver – this allows us to work out the most appropriate route of access (termed the ‘appropriate copy’) to an electronic resource. The OpenURL Router could point the way for this type of service – this service allows you to push OpenURLs to a centralised service, which then tries to route the OpenURL to your ‘local’ resolver. I believe it can do this either based on IP range the request is coming from, or via the specification of a parameter which is linked to concepts of Federated Access Management.
Perhaps with some further work, this could use Geolocation information with ‘nearest library with resolver’ information to push the OpenURL to the relevant resolver, and so offer walk-in access. Potentially this could be combined with information about printed collections if it was supported by the local link resolver, and so you could actually answer both ‘do you have this in print’ and ‘do you have this electronically’ in a single query.
Of course one of the problems is that the user is actually in multiple ‘contexts’ at one time. That is to say, if I’m sitting in one of the Oxford libraries, and I’m a student at the Open University, I have access to all of the Oxford library physical collection, the electronic resources they offer walk-in access to, and all the Open University’s electronic resources. I may even have access to other sets of resources via membership of another library or organisation completely separately. In an ideal world, what the user gets access to is informed by bringing together information from all these contexts, and delivering the resource to the user by whatever route is available.
This is clearly complicated – I sometimes wonder if the solution is for users to have their own OpenURL resolver that can draw on all the information relevant to them, as they are probably the only person who really understands their full context. This seems a rather unlikely scenario to be honest, although this recent blog post on e-books made me wonder if there was a market for an individual resolvers.
Erewhon
Erewhon is a project based at
OxfordUniversity looking at developing geolocation services and to improve mobile access to resources – being presented today at an Open University Library Seminar by Sebastian Rahtz and Tim Fernando. I hope I’ll have a chance to do a follow up blog post soon on how I think this work could be relevant to TELSTAR – but for now, you’ll just have to enjoy these very brief notes from the session.
Erewhon is funded (as is TELSTAR) under the JISC Institutional Innovation programme. The aim is to:
- Develop geolocation services
- Improve mobile access to resources
Erewho is predicated on a number of assumptions:
- Free mapping
- Mapping things using geographic metadata is become ubiquitous
- Institutional geodata will be available
- Locations of major buildings etc.
- Smart phones will become increasingly common (towards saturation)
- Increasingly there will be usefully personalised data in systems
- Users can supply their location automatically
- GPS, CellTower ID, Wifi ID, FireEagle etc.
Deliverables are:
- Implementation of a geolocation data model, syndication interface and API for organizational resources
- Provision of demonstration location-aware applications
- Adaptation of selected Sakai tools for use on relevant mobile devices
- Guidelines for others to implement similar tools
The project has a blog at http://oxforderewhon.wordpress.com/
Erewhon is not aiming to write the applications that make use of the geolocation data, but ensure there is a stable platform for such applications to be built on.
What are the issues with current approaches (e.g. Google maps)?
- Google location of political units is patchy and not always accurate
- Fixing the Google data when you find a mistake is cumbersome
- They do not model to the level of the entrance or room
- Their apparent knowledge of university structure is simply based on keyword searching
We need systems that can handle:
- Time based data
- Rich relationships
- More entities
- Extendable
RDF was the obvious way to go.
Decided to implement with Gaboto – an open source generic RDF storage engine that allows for automatic mapping from RDF to Java objects and is able to cope with time in RDF.
Result is 2nd generation of Oxpoints – it covers colleges, departments, libraries, museums and carparks, but also anything else one may encounter.
The types of objects that are recorded are things like:
- Building
- Division
- DrainCover
- Entrance
- Faculty
- Group
- Image (image related to the thing?)
- Room
- ServiceDepartment
- Site
- WAP
- Website
Have collecting information on about 1000 ‘political entities’- e.g. libraries etc.
Data collected from existing databases, web pages, walk-rounds, Google Earth, Estates department.
You can query Oxpoints for a KML results set – which can e.g. be pushed to GMaps.
http://maps.google.co.uk/?q=http://m.ox.ac.uk/oxpoints/colleges.kml
You can explore the dataset at http://m.ox.ac.uk/cgi-bin/oxshow.pl (no SPARQL endpoint at the moment though)
Mobile technology:
- About supporting more than just ‘reading email’
- Smartphone market eating into traditional mobile phone market
- Essentially – all phones will become ‘smart’
What are institutions doing with mobile technology:
- http://m.mit.edu
- iStanford app for iPhone
Oxford now has http://m.ox.ac.uk
This gives access to a selection of custom services including some which are firsts for any University:
- Let me listen to some podcasts by Humanities
- What’s my College Tutor’s name
- Where’s my nearest postbox and what time is it collected at?
- Which is the nearest library with book X
- How do I cycle from A to B?
Fast Development Process – Agile programming methodology with Continuous Integration (using Hudson). Site is built using Python and django framework.
An example of the type of application they want to be able to provide is real time bus information:
- DoT provided NaPTAN (National Public Transport Access Node) database under licence (free under educational license) – lists every bus stop, platform, port etc. with geocode
- Removed irrelevant data (bus stops that no longer exist, or aren’t currently used) – not a trivial task
Workflow is:
- Mobile user browses to m.ox.ac.uk
- Django gets items (e.g. bus stops) within a certain radius
- Use Open Street map to get some modified map tiles
- Then request bus data from oxontime.com
- Adds details to map and returns to browser
This is currently in private beta
Some other services that they are planning, or interested in are:
- Access webcam feeds from across Oxford
- Access to Results schedule (when different sets of results are released by the University)
- Get podcasts (on iPhone you can do that directly via iTunes, on other handsets stream to browser)
- Postbox (inc. collection times)
- Find nearest library holding a specific item (queries library catalogue using Z39.50)
To get Map locations in a mobile browser is a challenge – at the moment you need to have one of the following:
- Support for HTML5
- Support for GoogleGears
- Blackberry (can enable access to GPS in settings)
Routes of Dissemination
This blog is obviously one way in which we are trying to disseminate the work of the TELSTAR project. The recent presentation at ALT-C and resulting YouTube video of the presentation were other aspects of our dissemination work. I’m now looking at what the next steps should be.
Traditionally a JISC funded project like TELSTAR might produce some printed publicity materials, present at various conferences, maybe publish an article or two, and possibly have a blog or similar channel for dissemination. Of course, this would be alongside the formal written outputs of the project.
All of these seem quite reasonable approaches to disseminating project outcomes. However, with TELSTAR I perceive some particular challenges. Firstly, the short time the project has to run means that it is difficult to find conferences that are accepting papers and happen before the end of the project. Secondly, the potential audience for TELSTAR is broad (it may not be that unusual in this), meaning it is difficult to identify channels that reach all of the possible interested parties. Earlier this year Lawrie Phipps, who is the JISC Programme Manager for the Institutional Innovation strand that TELSTAR is funded under posted some thoughts about dissemination for educational technology projects.
Some brief, but (I think) interesting statistics:
- Audience at TELSTAR ALT-C presentation: 20-30 people (that’s a guess on my part)
- Views of YouTube video (after 5 days): 301 viewings (and they weren’t all me)
- This blog (since 23/8/09): 182 unique visitors, 294 visits, 468 page views
- Discussion generated by single post to code4lib mailing list: 58 emails
So, I thought I’d ask for suggestions – please leave comments below – how should we disseminate the work of the project? What works for you? Do you have any examples of excellent dissemination of project outcomes? What would you like to know?
ALT-C – the presentation
I was lucky enough to attend the ALT-C conference last week (you can read my general reflections on the ALT-C if you want), and even luckier (?) to have the chance to present on the TELSTAR project. If you weren’t able to make the live event (or if you were, but want more) – here it is:
It’s about 10 minutes long, and endeavours to outline the problems we are tackling, and the work we are doing.
Managing link persistence with OpenURLs
Statement of problem
Web resources can change location over time, or the route of access for users belonging to a specific institution can change with the same outcome, i.e. broken links. This is undesirable when providing links within teaching material where it is impractical to review and republish the material on a regular basis.
The current approach at the Open University is to create ‘managed’ links which are used in teaching material and environments instead of the primary link for a resource. These managed links are managed by two systems:
- For free web resources managed links are provided by ROUTES
- For subscribed web resources (e.g. databases) managed links are provided by a locally developed system
An example is that if we wish to include a link to the BBC homepage within the VLE we would not use the Primary URL:
but instead use the ROUTES created ‘managed’ URL:
Although this practice solves the problem of persistence over time (if the primary URL for the web resource changes, we can update the ROUTES or local system without having to update the course material), it creates several new problems:
- To provide a link to any web resource you have to know a special link, which you have to ask for from the library
- The ‘managed’ URLs do not make sense outside the context of the OU, meaning that if a student copies a reference to a resource, including the link, these references are not really appropriate for use except within the OU environment
- The library has to ‘manage’ URLs for all referenced resources, no matter whether the Primary URL is correct or not
Business Requirements
In order to avoid these issues we need a solution which:
- Preserves the Primary URL in the original reference
- Does not require the entry of a special ‘managed’ URL by course authors or others involved with the authoring and editorial process
- Does not require management of Primary URLs which are valid
Proposed Solution
The proposed solution is that we should use OpenURL to provide links to resources wherever possible. For bibliographic formats – journals, journal articles, books (whether in print or electronic) the expression of these in OpenURL is well documented, and the translation of the OpenURLs generated by link resolvers is well understood.
However, when providing links to a web resource, the use of OpenURL is novel. What it will allow us to do is to take a Primary URL, check whether there is a Managed URL for it and direct the user to the Primary or Managed URL depending on what is available.
The flow would be as follows (using the OU OpenURL resolver, which is an SFX implementation):
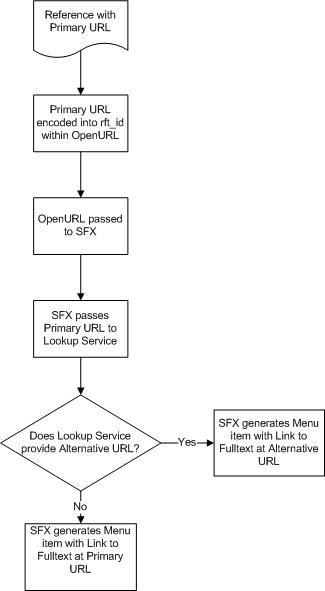
Boxing Clever
About 10 days ago Tony Hirst (@psychemedia) posted a new mashup on the Ouseful blog called DeliTV. The work was prompted by his use of video clips as part of the T151 Digital worlds course at the Open University. In his original blog post Tony describes how he wanted
– a browser based or multiplatform delivery interface that would allows users to watch video compilations on a TV/large screen in lean back mode;
– a way of curating content and generating hierarchical playlists in which a course could have a set of topics, and each topic could contain one or more videos or video playlists. Ideally, playlists should be able to contain other playlists.
What Tony hit on was using the Delicious bookmarking service to create lists of videos (by use of tagging), and the open source Boxee software, which brings together media viewing and aspects of social networking. Tony built some Yahoo Pipe work to take an RSS feed from Delicious and gave you a feed of videos that Boxee could consume, and from there give you a video playlist.
It is this type of use of resources within Open University courses that the Telstar project is concerned with, so I was interested to see whether we could do a similar thing with the platforms we are using for the project – specifically the RefWorks reference management software. I’m glad to say, the answer is ‘yes’.
The key things that makes this possible is the fact you can share items from RefWorks using a function called ‘RefShare’. This allows you to publish a set of resources in your RefWorks account on the web, and optionally include an RSS feed. I was then easily able to copy Tony’s Yahoo Pipe and modify it slightly to make it work with the RSS feed provided by RefShare – and at the Boxee end the functionality is exactly the same, because that deals with the output from the Yahoo Pipe in exactly the same way – one of the beauties of using RSS to push information around the web.
A couple of questions you might have are:
- How exactly do you do this?
- Why use RefWorks/RefShare instead of Delicious
I’ll tackle the second question first. There are several reasons the Telstar project is looking at RefWorks as a basis for delivering references and resources into a teaching environment, but perhaps the major one is that RefWorks is designed to allow you to output references in a wide variety of referencing and citation styles. This is something that is both required when writing Open University course material, and something we require of students when they submit work for assessment – but it can be a fiddly and time consuming process. Using RefWorks you can output all the references you’ve used in the correct citation format – hopefully all the hardwork is done for you behind the scenes. Simple bookmarking services like Delicious lack this functionality, and in general don’t store enough information to deliver full academic references.
We are also developing integrations between the Moodle VLE used by the Open University and RefWorks, which might confersome additional benefits to using RefWorks – the ability to import references from RefWorks into the Open University VLE (Moodle), or subscribe to a RefShare RSS – so if you built the video playlist in RefWorks you could share into the VLE as well. Also for all items in RefWorks, it is a one-click process for students to take a copy of the reference into their own RefWorks account.
Obviously Delicious has some real advantages as well – it is very easy to use, bookmarking and tagging extremely simple, ‘sharing’ is default rather than a decision, and it has a ecosystem of users/developers built up around it. I think particularly the simplicity of bookmarking, tagging and sharing make it more ‘lightweight’ than RefWorks – and I can see that as a big selling point for those building lists of resources – it’s something I’m thinking about a lot as part of the project – how to get resources into RefWorks.
Anyway, that’s the why, what about the how?
First you’ll need a RefWorks account of course. You’ll need to belong to a subscribing institution to do this, so if you belong to a University, ask your library. Specifically if you are at the Open University, have a look at the details at http://library.open.ac.uk/research/bibliomgt/index.cfm#refworks (I’ll be the first to admit this is a bit fiddly, but you only have to do it once!)
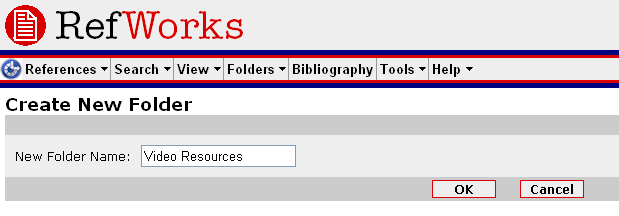
Once you’ve got your account/logged on, you will need to create a folder (RefWorks doesn’t use ‘tagging’ but rather organises references into folders – but as a single reference can belong to many folders, it works out as basically the same thing). So find the ‘Folders’ menu and select ‘Create New Folder’:

Enter a name for your folder
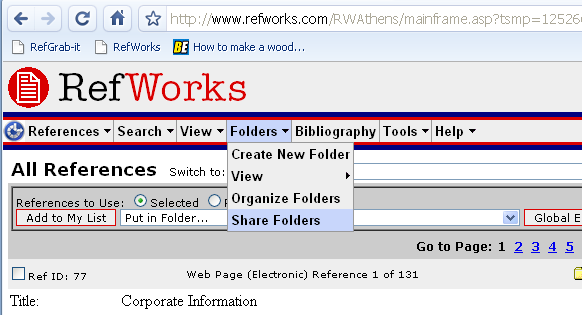
Click OK. Then you need to Share the folder – go to the ‘Share Folders’ option on the Folders menu:
You should see a list of all your folders with the option to Share them – click the ‘Share Folder’ option:
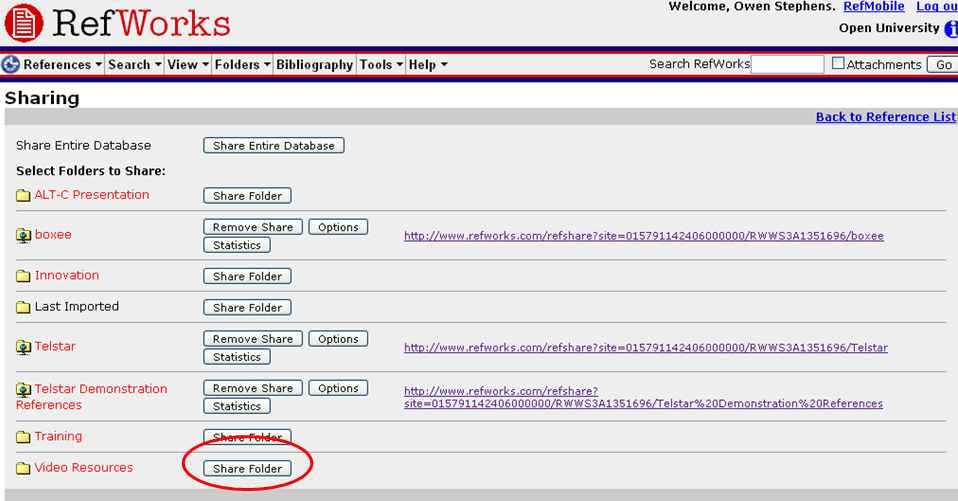
You will then see the Shared Folders options – you need to set the ‘Create RSS Feed’ option – you can decide how many items you display in the RSS feed up to 50 (there are some ways around this limitation if necessary, but I’m not going to go into it now). You also need to give it a Title (otherwise it won’t let you create the RSS Feed).
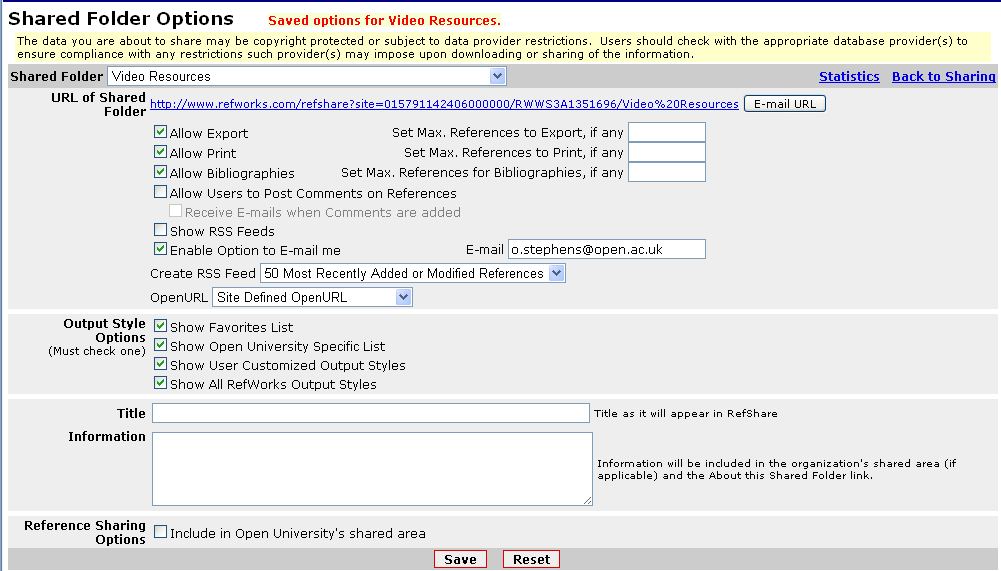
On the option page, you can see a link for the Shared Folder – in this case:
http://www.refworks.com/refshare?site=015791142406000000/RWWS3A1351696/Video%20Resources
You can either visit this page, and then follow the link to the RSS feed, you you can simply add ‘&rss’ to the end of the URL:
http://www.refworks.com/refshare?site=015791142406000000/RWWS3A1351696/Video%20Resources&rss
OK, now you are ready to start adding resources to the folder. You can do this by hand, but I’d suggest using the RefGrab-it bookmarklet/browser plugin – details are at http://www.refworks.com/Refworks/help/Refworks.htm#Using_RefGrab-It_to_Capture_Web_Page_Data.htm. I use the bookmarklet with Chrome, and it works well.
Then browse to the page you want to bookmark. Now, I haven’t tested all of these, but in theory as I’m using the same Pipes code as Tony, his list of what you can bookmark holds true:
At the current time, you can bookmark:
- a particular Youtube video
- (http://www.youtube.com/watch?v=YC8Kk9nEM0Y);
- a Youtube Playlist
- (http://www.youtube.com/view_play_list?p=11DBE3516825CD0F);
- recently uploaded videos to a particular user’s Youtube channel
- (http://www.youtube.com/user/bisgovuk);
- programmes listed in a BBC iPlayer category feed
- (e.g. http://www.bbc.co.uk/programmes/genres/drama/thriller);
- a Deli TV playlist
- (http://delicious.com/psychemedia/t151boxeetest);
- an MP3 file
- (e.g. http://www.downes.ca/files/audio/downeswiley4.mp3);
- a “podcast” playlist
- (http://delicious.com/psychemedia/wileydownes+opened09).
If any of these don’t work, you can let me know and I’ll have a look.
When you have browsed to a page, hit the RefGrab-it Bookmarklet (or plugin) and you’ll get the option to save it. The plugins are a bit more powerful as you might expect. If you use the bookmarklet, it will look something like this:
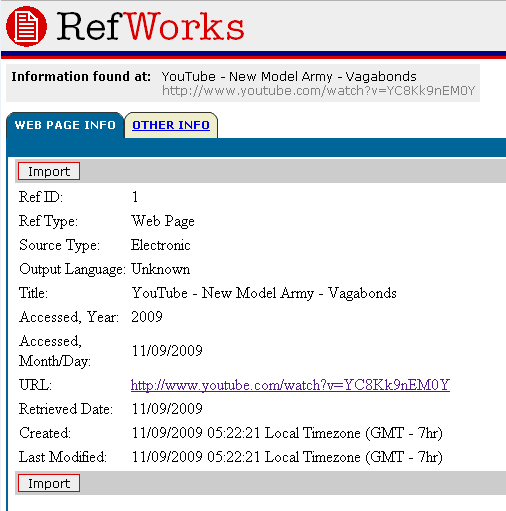
You can then Import it. You’ll get this screen:
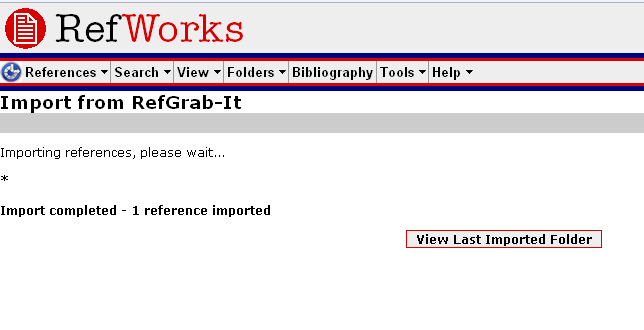
If you then click ‘View Last Imported Folder’, you can put the Reference immediately into your shared folder:
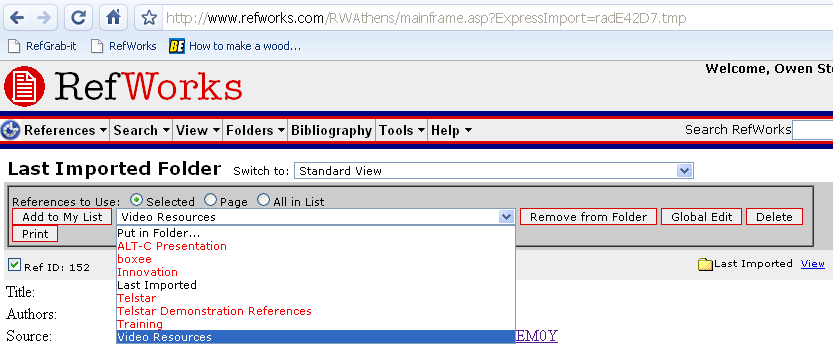
(remember to check the box next to the Reference – a green tick to the left of the Ref ID)
Now you need to get the Pipe feed. Go to the Pipe I’ve created at http://pipes.yahoo.com/pipes/pipe.info?_id=f78732dea457b2e7c4a6415abf7c14c3 and enter the URL for your RefShare RSS feed (remember the RSS feed, not just the RefShare folder URL). Run the pipe, and click on ‘Get as RSS’ – this will give you the URL you need to feed into Boxee – and now we are back into Tony’s workflow – see his instructions for adding a feed to Boxee.
Hopefully that’s enough to get you going. When I can find some time I’m going to look at the Pipe again, but for now treat it as testing only, and it may break.